Michael Tynes, Wenhao Gao, Daniel J. Burrill, Enrique R. Batista, Danny Perez, Ping Yang, and Nicholas Lubbers (2021)
Highlighted by Jan Jensen
TOC picture from the paper (c) 2021 ACS
This paper tries to solve two problems at once: data augmentation for small data sets and a method-independent uncertainty quantification (UQ). Data augmentation is quite common in areas like image classification where images can be perturbed (e.g. rotated by a few degrees) and still be recognisable. However, this is difficult in chemistry where small perturbations in structure can have a non-negligible effect on properties. For text-based molecular representation once can use non-canonical smiles for augmentation, but there is no generally applicable method.
Similarly, most UQ methods are specific to the machine learning model-type, with the exception of ensemble methods that requires the training and deployment of several models, which can be expensive.
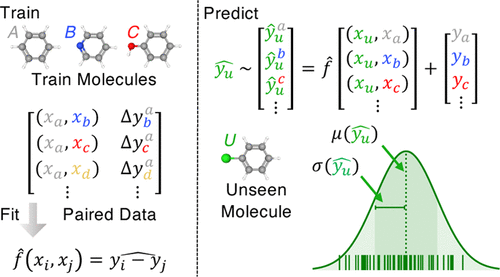
The paper offers a simple solution to both. The method is trained to reproduce the ground truth difference for all $n^2$ molecule pairs thereby increasing the training set size significantly. When making a prediction for a new molecule, the model predicts the differences relative to all training set molecules with the standard deviation serving as a measure of prediction uncertainty. Pretty neat idea and easy to implement! The main change is to construct molecular representations for the molecule pairs but the authors outline one easy-to-implement approach.
Depending on the task and training set size the data augmentation decreases the MAE by 3-40%. UQ quality is notoriously difficult to quantify, but the method appears to give uncertainties similar to those obtained by a random forest method.

This work is licensed under a Creative Commons Attribution 4.0 International License.
This work is licensed under a Creative Commons Attribution 4.0 International License.
No comments:
Post a Comment